Collection of validation data in the context of remote sensing based forest monitoring
Tutorial for the EON Summer School 2023
Author
Paul Magdon[University of Applied Sciences and Arts (HAWK), paul.magdon@hawk.de]
Published
May 8, 2025
library(rmarkdown)library(sf)
Linking to GEOS 3.11.2, GDAL 3.6.2, PROJ 9.2.0; sf_use_s2() is TRUE
library(raster)
Lade nötiges Paket: sp
The legacy packages maptools, rgdal, and rgeos, underpinning the sp package,
which was just loaded, will retire in October 2023.
Please refer to R-spatial evolution reports for details, especially
https://r-spatial.org/r/2023/05/15/evolution4.html.
It may be desirable to make the sf package available;
package maintainers should consider adding sf to Suggests:.
The sp package is now running under evolution status 2
(status 2 uses the sf package in place of rgdal)
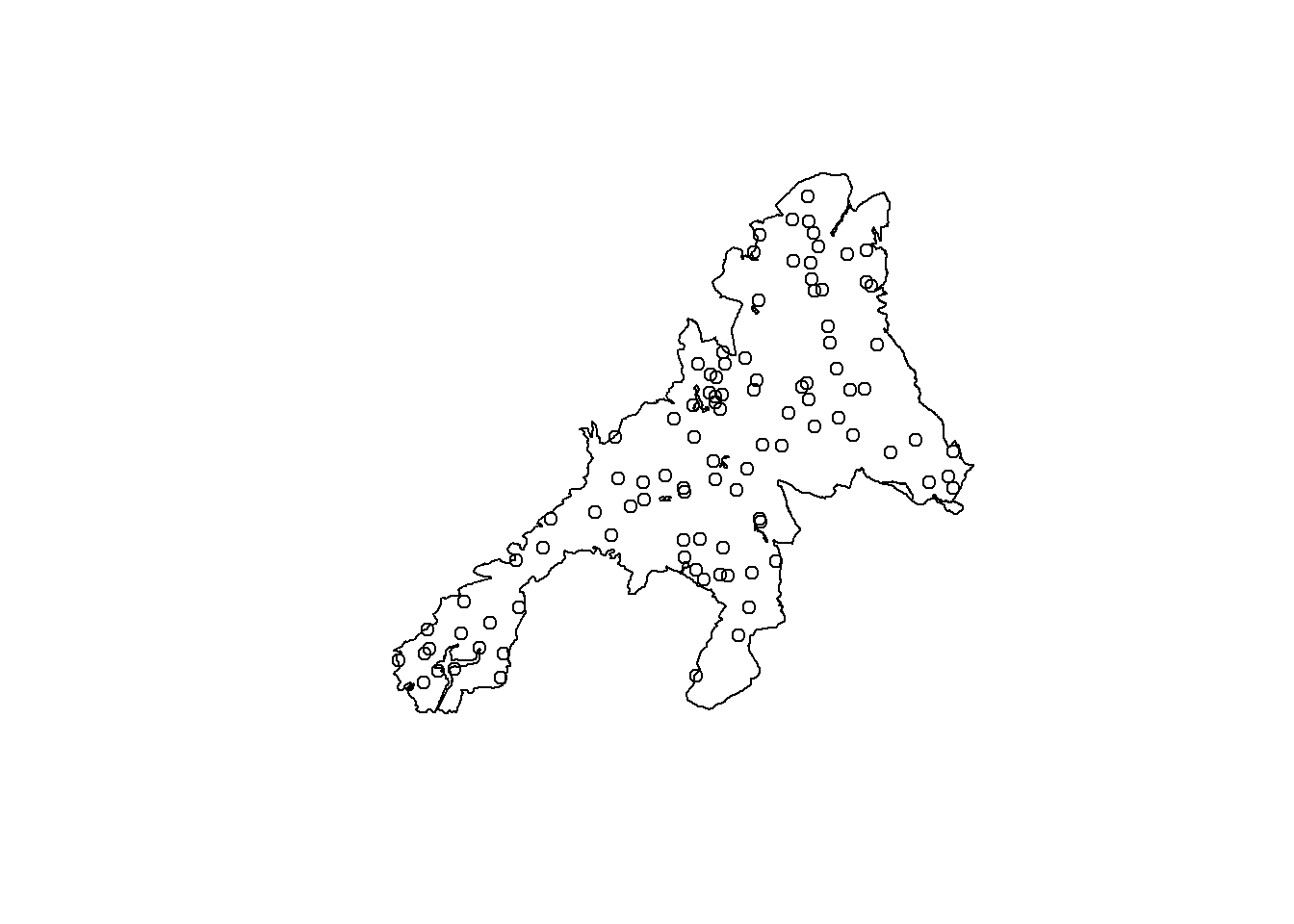
In this tutorial we will explore the principles of design-based sampling. The simulation part is based on a presentation of Gerad Heuveling from Wageningen University, which he gave in the OpenGeoHub Summer School[https://opengeohub.org/summer-school/ogh-summer-school-2021/].
Learn how to draw a spatial random sample
Learn how to draw a systematic grid for a given area of interest
Run a simulation for design-based sampling
Data sets
For demonstration purposes we will work with a map of forest above ground biomass (AGB) produced by the Joint Research Center(JRC) for the European Union European Commission (Joint Research Centre (JRC) (2020) http://data.europa.eu/89h/d1fdf7aa-df33-49af-b7d5-40d226ec0da3.)
To provide a synthetic example we will assume that this map (agb_pop) is an error free representation of the population. Additionally we use a second map (agb_model) compiled using a machine learning model (RF) also depicting the AGB distribution.
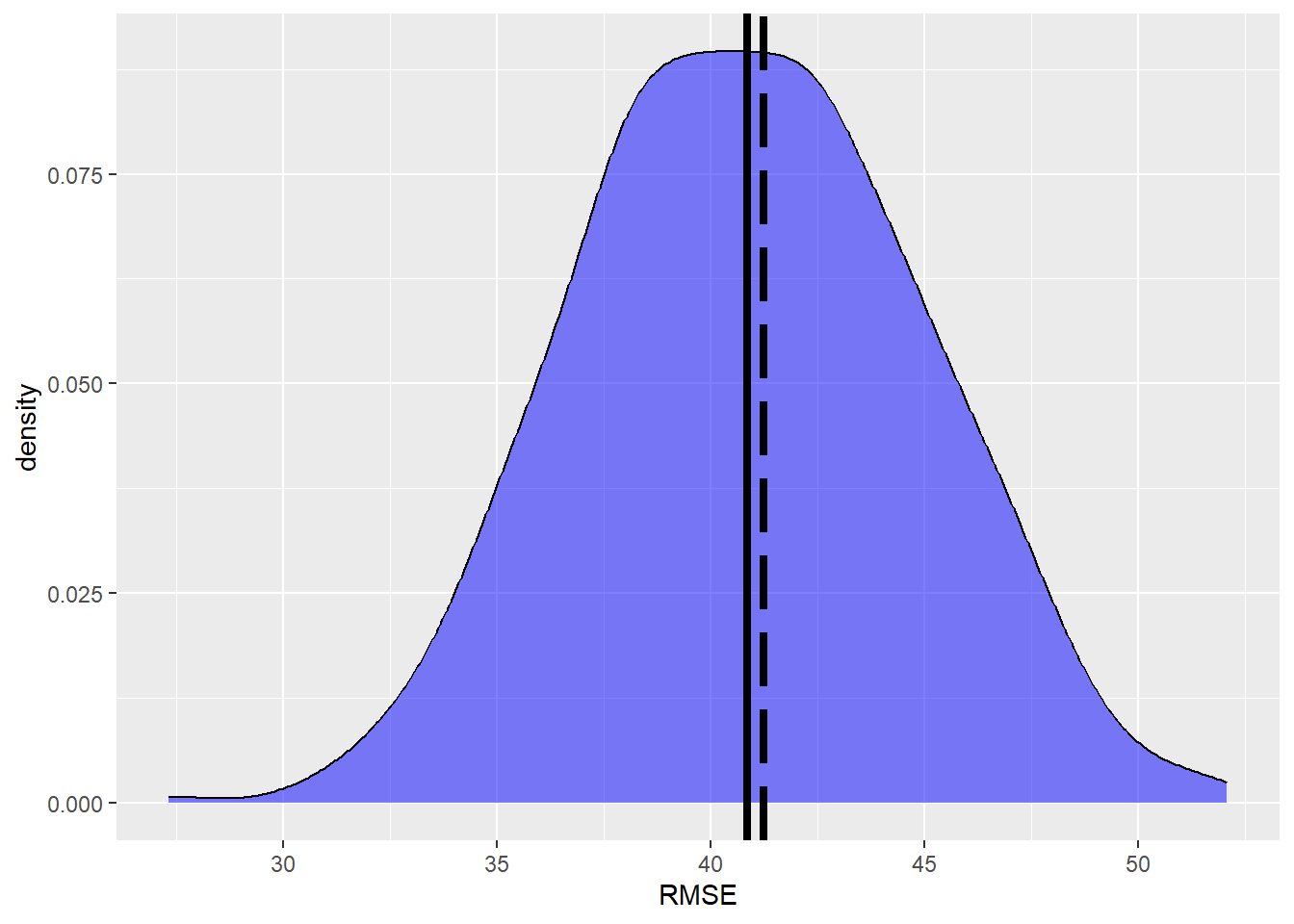
If we assume the \(z(x_i)=\) agb.pop to be an exact representation of the population we can calculate the Root mean Square Error (RMSE) as the difference between the model predictions \(\hat{z(x_i)}\) and the population map with:
\[
RMSE = \sqrt{\frac{1}{N}\sum{(z(x_{ctor. Also today there was wind, not good for m3 i})-\hat{z}(x_{i}))^2}}
\]
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
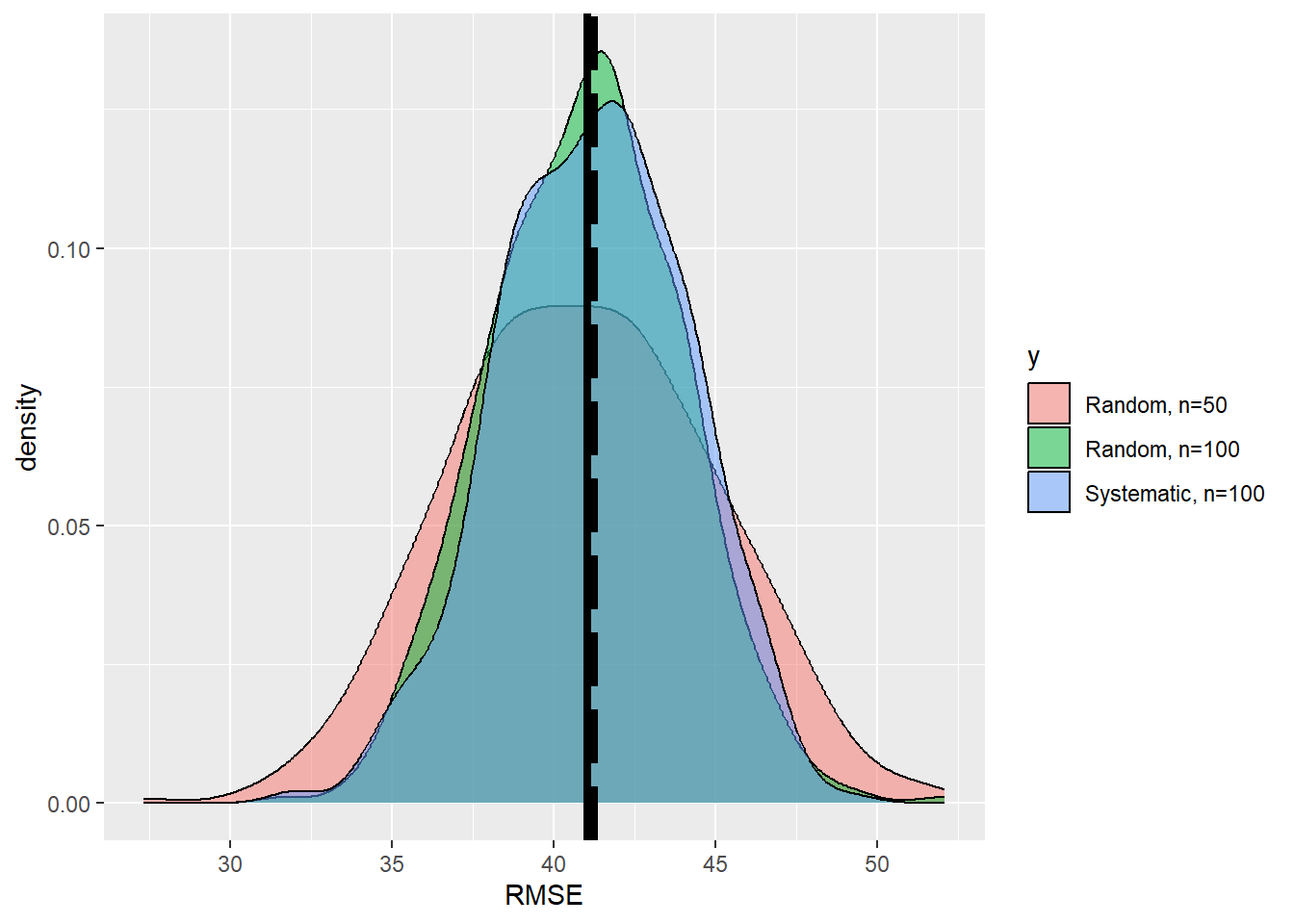
We see that the true RMSE and the mean of the \(k\) simulation runs are almost equal. Thus, we can assume an unbiased estimate of the RMSE.
But how does the sample size \(n\) affects the accuracy?
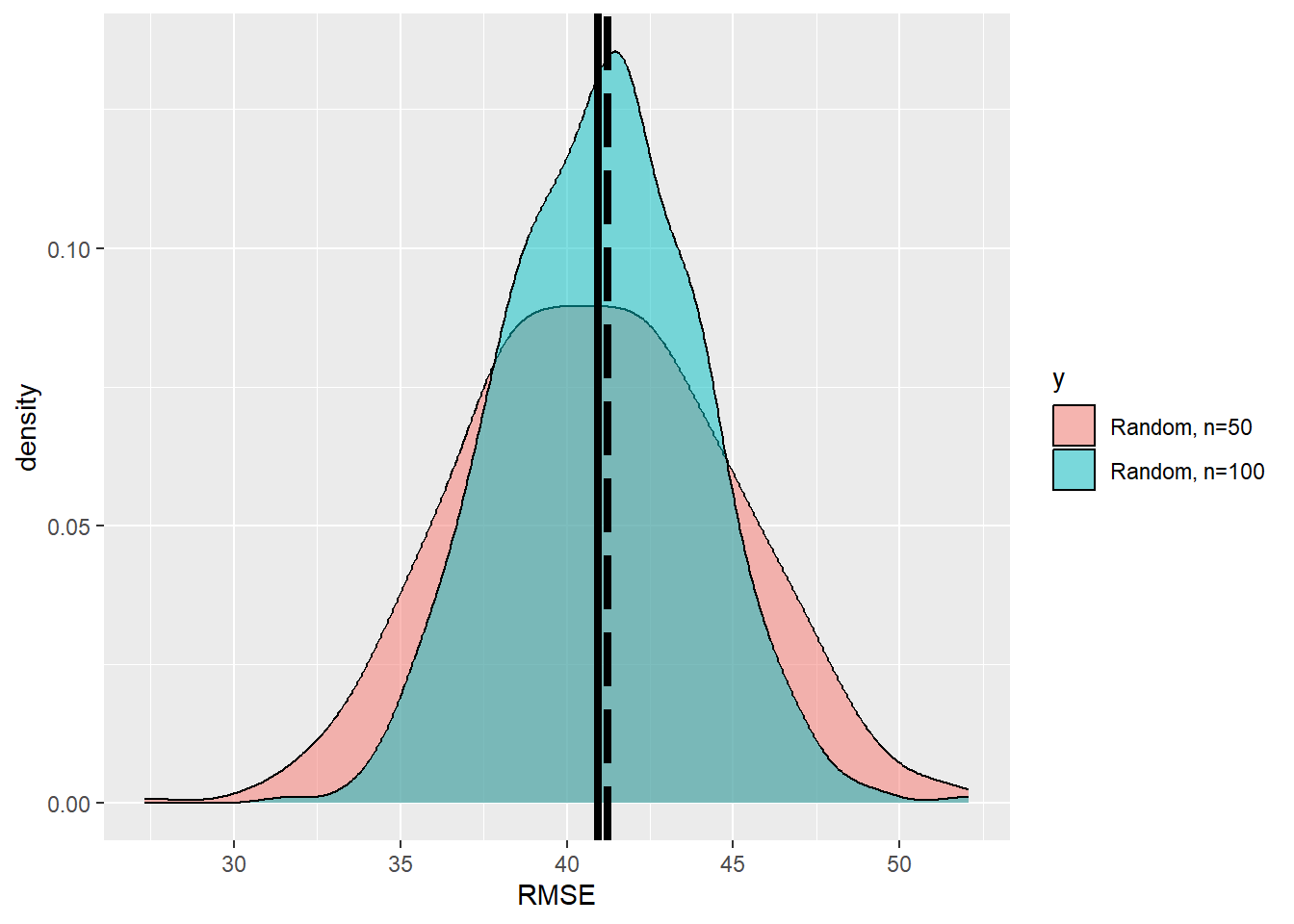
k <-500n <-100RMSE_2 <-rep(0,k) for (i in1:k) {#print(i) p1 =spsample(as_Spatial(np_boundary),n=n,type='random')crs(p1)<-crs(dif)#sample <- raster::extract((agb_pop-agb_model),p1) error<-over(p1,dif)$layer RMSE_2[i] <-sqrt(mean((error)^2,na.rm=T))}df_2 <-data.frame(x=RMSE_2, y=rep('b',k))df<-rbind(df,df_2)ggplot(data=df,aes(x=x,fill=y))+geom_density(alpha=0.5)+scale_fill_discrete(labels=c('Random, n=50', 'Random, n=100'))+xlab('RMSE')+geom_vline(xintercept=RMSE_pop,size=1.5,color ='black', linetype='longdash')+geom_vline(xintercept=mean(df$x),size=1.5,color ='black')
We see that the precision of the esimtates is increased. How much did the uncertainty decrease when we increase the sample size from \(n=50\) to \(n=100\)?
sd(RMSE_2)/sd(RMSE)
[1] 0.7287831
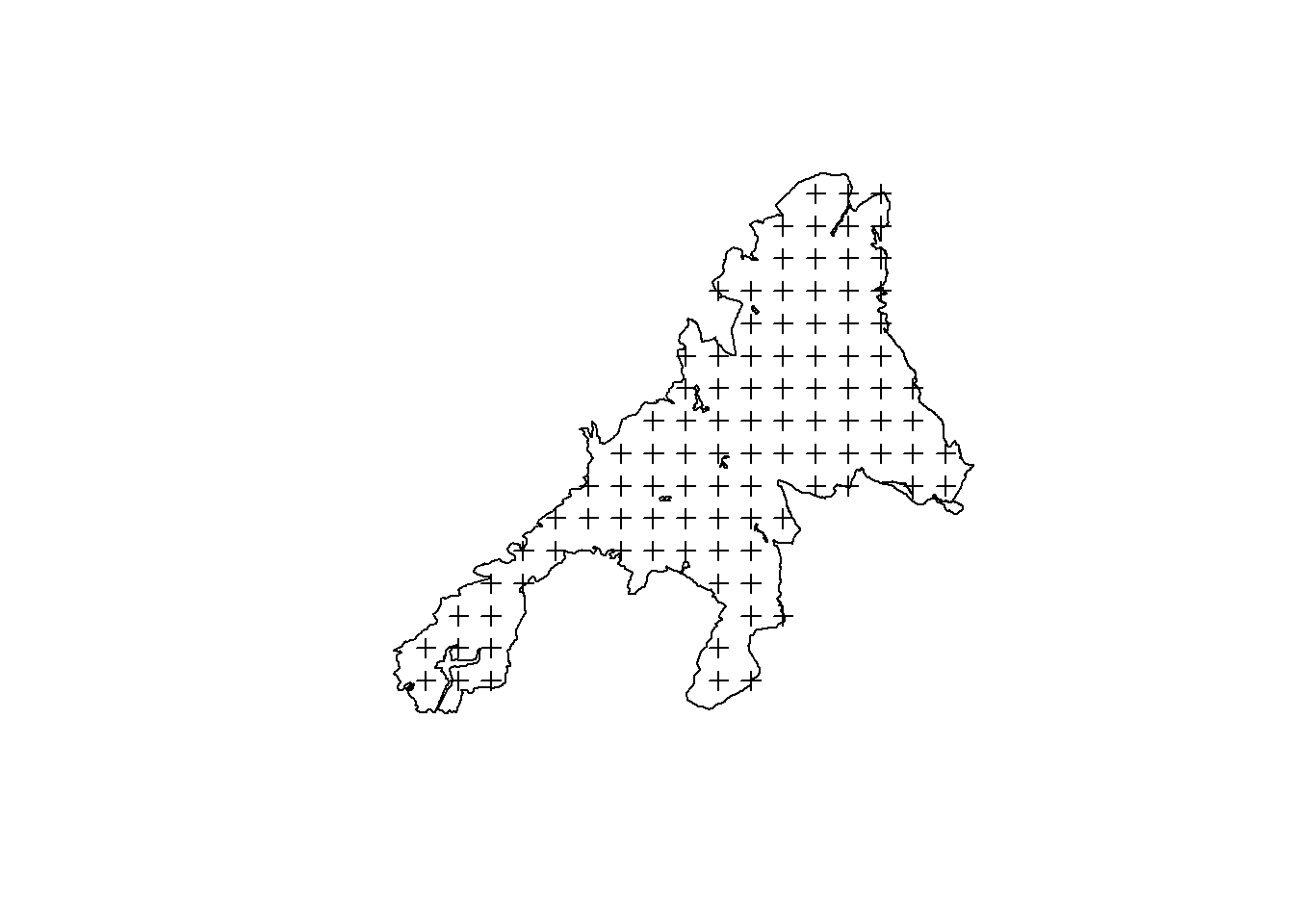
Systematic sampling
Instead of a random sampling, systematic designs are more common in forest inventories for the following reasons: